A Review of Optimization by PROmpting(OPRO).
Tags: tech, llms, prompt engineering
Why is Prompt Optimisation important?
LLMs are shown to be sensitive to the prompt format (Zhao et al., 2021; Lu et al., 2021; Wei et al., 2023; Madaan & Yazdanbakhsh, 2022); in particular, semantically similar prompts may have drastically different performance (Kojima et al., 2022; Zhou et al., 2022b; Zhang et al., 2023), and the optimal prompt formats can be model-specific and task-specific (Ma et al., 2023; Chen et al., 2023c). Therefore, prompt engineering is often important for LLMs to achieve good performance (Reynolds & McDonell, 2021). However, the large and discrete prompt space makes it challenging for optimization, especially when only API access to the LLM is available. Prior work on continuous and discrete prompt optimization (Lester et al., 2021; Li & Liang, 2021; Zhou et al., 2022b; Pryzant et al., 2023) assumes a training set is available to compute training accuracy as the optimization objective. Studies show that optimizing prompts for accuracy on a small training set is often sufficient to achieve high performance on a test set.
What is OPRO?
OPRO (Optimization through Prompting) introduces a revolutionary framework by leveraging Large Language Models (LLMs) as optimizers, enabling users to frame optimization problems in natural language rather than complex code or formulas. This approach holds the potential to democratize optimization, making it more adaptable and accessible.
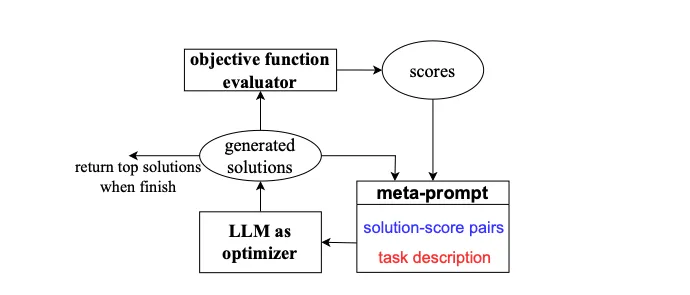
OPRO reframes the optimization process by allowing users to describe their problem, constraints, and desired solution characteristics through a structured meta-prompt. This meta-prompt includes not only the problem setup but also a record of previous solutions and their corresponding scores, forming an optimization trajectory that the LLM uses to iteratively refine new solutions.
OPRO’s significance lies in three key advantages:
-
Accessibility:
By using natural language descriptions, OPRO removes the barrier of requiring advanced mathematical or programming skills, making it feasible for non-experts to tackle complex optimization tasks. -
Adaptability:
Switching tasks in OPRO is as simple as updating the problem description in the meta-prompt, making OPRO highly adaptable to a wide range of challenges. -
Novel Approach:
Unlike traditional gradient-based methods, OPRO works without derivatives, opening new doors for solving complex problems, especially those involving discrete search spaces or non-differentiable functions.
Case Studies in Optimization with LLMs
To demonstrate the potential of LLMs for optimization, OPRO can be applied to classic problems such as linear regression and the traveling salesman problem (TSP), two foundational challenges in mathematical optimization and operations research.
- For linear regression, LLMs generate candidate solutions by describing problem constraints and objectives in natural language, simplifying the problem-solving process.
- For TSP, LLMs can approximate optimal or near-optimal routes among a series of nodes, showing their capability in handling combinatorial optimization tasks.
On small-scale optimization problems, these case studies reveal that LLMs are capable of finding high-quality solutions via prompting and, in some cases, matching or surpassing hand-designed heuristic algorithms.
Key Components of OPRO
1. The Goal
The primary objective of OPRO in prompt optimization is to identify the prompt that maximizes the performance of a scorer LLM for a given task, such as text classification or summarization. The optimization process is guided by a training and test set, enabling objective measurement of each prompt’s effectiveness.
2. The Setup
- Scorer LLM: The LLM used to perform the task, whose performance OPRO aims to improve.
- Optimizer LLM: The LLM responsible for generating and refining candidate prompts.
- Training Set and Test Set: The training set is used to evaluate prompt performance during optimization, while the test set is reserved for assessing the generalization ability of the final prompt.
3. The Meta-Prompt
At the heart of OPRO lies the meta-prompt, structured to guide the optimizer LLM in generating effective prompts. The meta-prompt consists of:
- Optimization Trajectory: A history of previously tested prompts and their scores, providing the LLM insight into effective prompt structures.
- Task Description: A concise, natural language summary of the task, often supplemented with example inputs and outputs to clarify the task’s requirements.
- Meta-Instructions: Instructions for the optimizer LLM itself, specifying the objective (e.g., accuracy improvement) and any constraints (e.g., prompt length or style).
- Instruction Position Placeholder: This placeholder indicates where the prompt should be inserted relative to the task inputs and outputs. Positions include
Q_begin(before the question),Q_end(after the question), andA_begin(before the answer), allowing flexibility for task-specific optimization.
Optimization Process
Each optimization step in OPRO generates new prompts with the aim of improving task accuracy, based on a trajectory of previously generated prompts. This approach contrasts with recent methods that iteratively edit a single input prompt (Pryzant et al., 2023) or constrain new prompts to adhere to a consistent semantic meaning (Zhou et al., 2022b). By leveraging the entire optimization trajectory, OPRO enables the LLM to gradually create prompts that enhance task accuracy.
The OPRO process follows a straightforward yet effective iterative workflow:
- Initialization: Starts with an initial prompt or an empty string.
- Iterative Refinement: The optimizer LLM is tasked with generating new prompts based on the meta-prompt.
- Evaluation: Each prompt is paired with training examples and tested on the scorer LLM, and the prompt’s score is recorded.
- Update Meta-Prompt: Newly generated prompts and their scores are added to the optimization trajectory, while lower-scoring prompts may be discarded to maintain the context window within the LLM’s limits.
- Repeat: This process iterates until a predefined number of rounds or a satisfactory score is achieved.
Output
The optimal prompt – the one with the highest score on the training set – is selected as the final output of the OPRO process. This prompt is then evaluated on the test set to assess its generalization performance.
Limitations of OPRO
While OPRO offers significant advantages, it also faces certain limitations. These challenges reflect both the inherent constraints of LLMs and the specific demands of optimization tasks:
-
Scale:
The meta-prompt’s length is constrained by the LLM’s context window, limiting OPRO’s applicability to simpler problem instances. Large-scale problems or those requiring detailed descriptions may exceed the LLM’s capacity. -
Complex Landscapes:
Optimization problems with irregular, multi-peaked loss landscapes can pose difficulties for OPRO. The LLM may become trapped in local optima, hindering consistent improvement. -
Overfitting:
During prompt optimization, OPRO may overfit to the training set used for prompt evaluation. While optimized prompts often generalize well, overfitting can still reduce performance on unseen data. -
Hallucination and Repetition:
The optimizer LLM may generate nonsensical or repetitive prompts, even when instructed otherwise. This reflects ongoing challenges with LLM reliability, necessitating careful monitoring of generated outputs.
Conclusion
OPRO represents a paradigm shift in optimization, allowing users to harness the power of LLMs by describing their problems in natural language. By lowering technical barriers, OPRO holds transformative potential for applications ranging from prompt optimization to solving complex discrete optimization problems.
Despite its limitations, OPRO’s novel approach offers an exciting glimpse into the future of optimization, where natural language and artificial intelligence converge to unlock new possibilities. As LLM capabilities evolve and larger context windows become available, OPRO may pave the way for increasingly sophisticated optimization solutions accessible to all.
Citations
This article is based on concepts discussed in LARGE LANGUAGE MODELS AS OPTIMIZERS by Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen.